Python owns AI/ML, and that is not changing. It rules the space for good reason: the ecosystem is unmatched, the syntax keeps research readable, and most teams can move from idea to experiment faster in Python than anywhere else. Rust is not trying to replace that layer. Under the hood, though, Rust keeps taking over the performance-critical parts of the stack: tokenizers, dataframes, model serialization, package management, and inference engines. This post explains where that shift matters, why it is happening, and how to use both languages without rewriting a working project.
Where the bottleneck actually is
This is not a "rewrite it in Rust" argument. Python's dominance in ML comes from ecosystem depth and iteration speed, not from raw interpreter performance. Most of the heavy math never ran in Python anyway. NumPy, PyTorch, and similar libraries dispatch work to compiled C, C++, and CUDA kernels. When the job is one large matrix multiply on a GPU, the language driving the script barely matters.
The expensive part is usually everything around the GPU: loading data, preprocessing, tokenization, serving, and orchestration glue. When that CPU-side work is slow, the GPU sits idle between batches. You end up paying for accelerator hardware while the pipeline waits on interpreter-speed code.
Why Rust wins on CPU-bound work
Rust compiles to native machine code. There is no interpreter loop, no per-operation dynamic dispatch, and no heap boxing for every integer. For parsing, string manipulation, feature engineering, and custom logic on structured data, Rust often runs one to two orders of magnitude faster than pure Python.
Python pays a cost on every loop iteration: reference counting, type checks, and dictionary lookups. Vectorizing into NumPy or pandas helps until the logic does not fit a vectorized shape. Ragged data, per-record branching, and custom tokenization usually drop you back into a Python-speed hot loop.
Rust also avoids trading clarity for speed. Iterators, generics, and pattern matching compile down to efficient machine code, so you can keep readable source without dropping into C extensions.
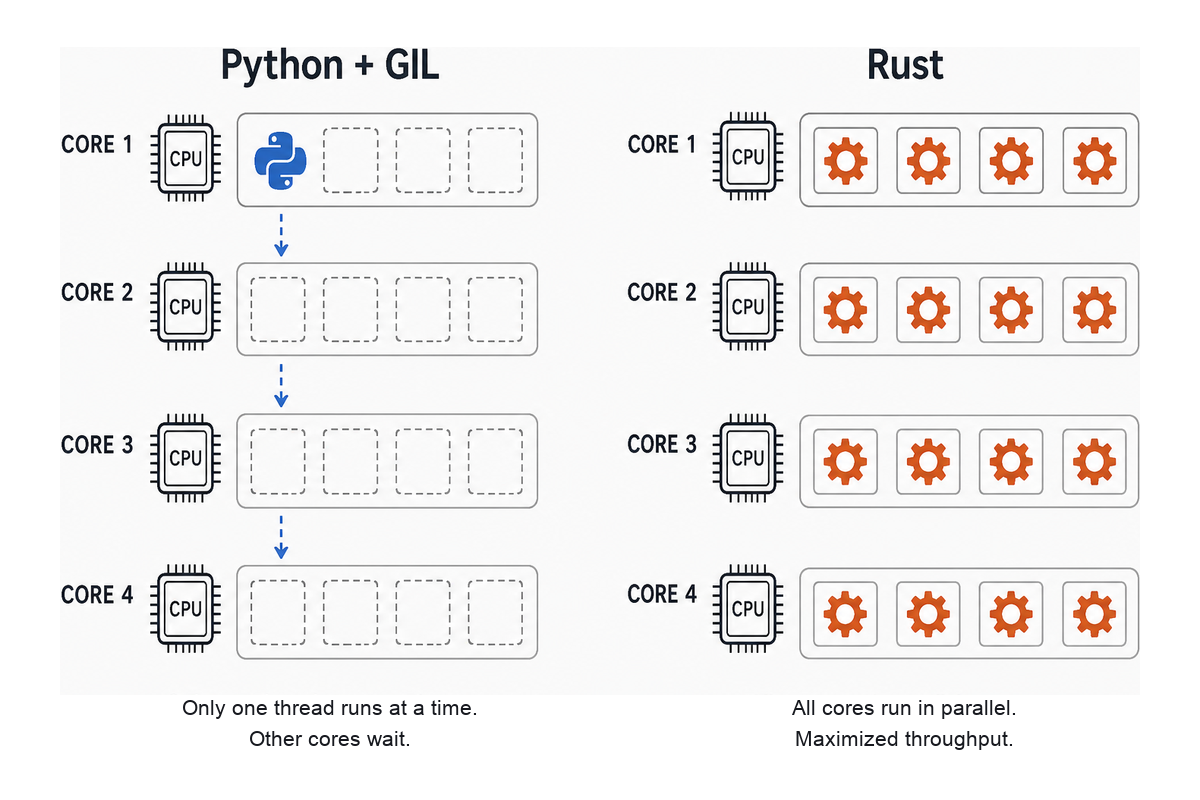
The GIL limits real parallelism in Python
CPython's Global Interpreter Lock allows only one thread to execute Python bytecode at a time. A multithreaded Python program on a 32-core machine still spends most of its time on one core. NumPy releases the GIL inside C routines. Python 3.13 introduced an experimental free-threaded build; Python 3.14 made that mode officially supported under PEP 779, with further performance work and a smaller single-threaded penalty than the 3.13 preview. Even so, the default interpreter still enables the GIL, the free-threaded build remains a separate install, and not every C extension is ready yet. Most production ML stacks still hit the wall shown below.
Rust has no GIL. Threads are real OS threads, and the ownership model catches data races at compile time.
The common workaround is multiprocessing, which sidesteps the GIL with separate processes. That works, but process startup has a cost, and every object crossing a process boundary gets pickled and copied. For large tensors and dataframes, serialization overhead can erase the gain. Free-threaded Python 3.14 offers another path for CPU-bound threading without pickling, but until the ecosystem and default builds catch up, Rust-backed libraries and process pools remain the practical answer for most teams.
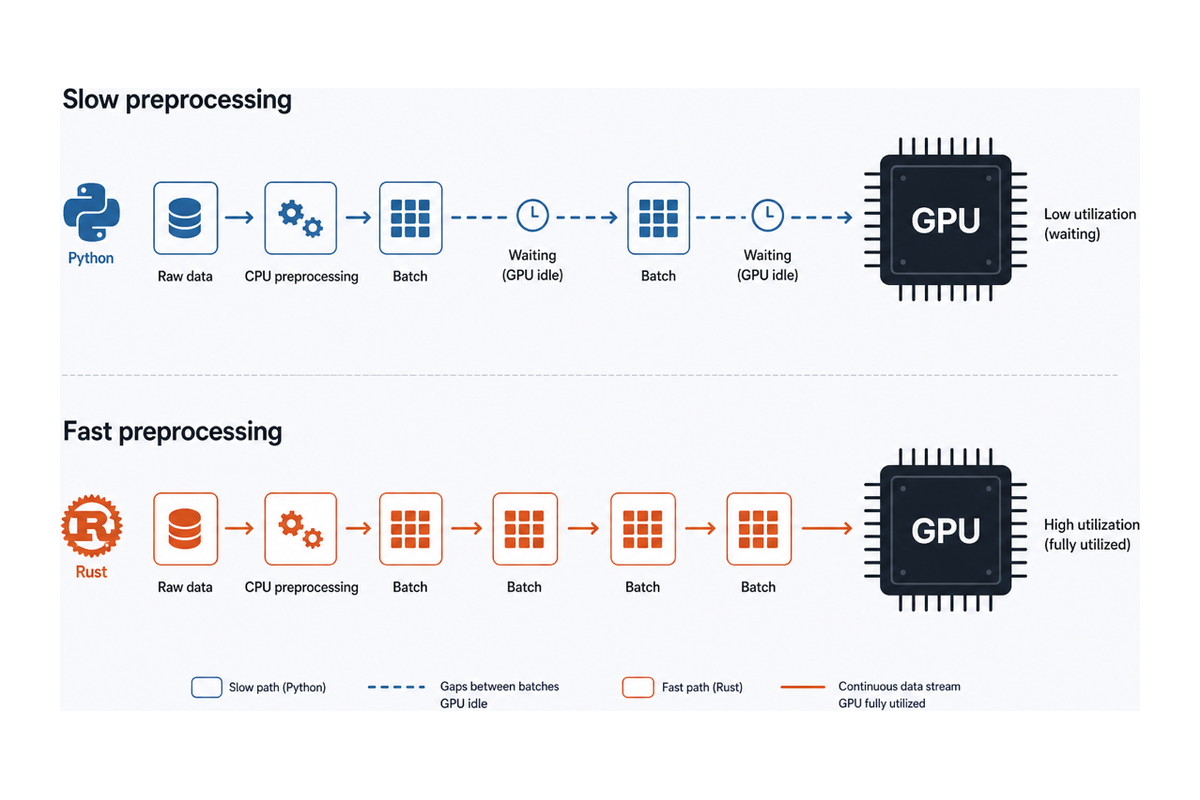
That is why so many hot-path libraries are written in Rust: Hugging Face tokenizers, Polars, and safetensors. Most Python teams already use them without writing any Rust themselves.
Concurrency and safety in production
Rust's ownership model makes many data races a compile error. The Send and Sync traits define what can move between threads, and the borrow checker rejects unsynchronized shared mutation. Parallelism is often a small change: with rayon, iter() becomes par_iter(). With tokio, an inference server can handle many concurrent connections on a modest thread pool.
On the security side, safe Rust rules out entire classes of memory bugs that still show up in native extension code. Serialization is another practical gap: pickle executes code on load, which makes legacy checkpoints a deserialization risk. safetensors exists partly because the ecosystem needed a format that is fast and cannot execute arbitrary code. Rust's type system also forces explicit handling of missing values and errors, which reduces whole classes of production surprises in long-running pipelines.
Supply chain risk exists on both sides. PyPI's scale makes typosquatting and account takeover a recurring problem. crates.io is smaller and has strong audit tooling, but no registry is immune. Rust's main security win here is removing memory-unsafety and unsafe deserialization from the native layer you depend on.
How the stack is actually layered
The pattern that keeps winning is a Python control plane over a Rust data plane. You write experiments and orchestration in Python. The heavy lifting runs in Rust libraries underneath.
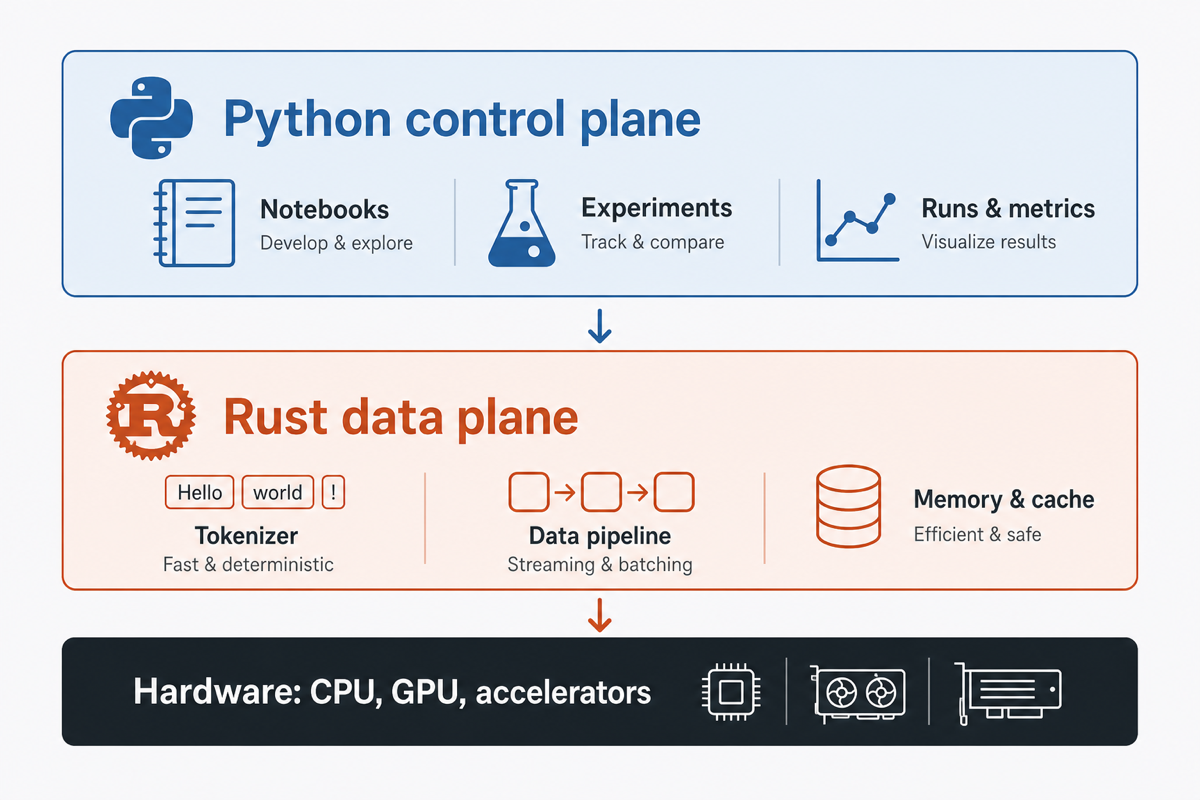
When profiling shows one Python hot path that vectorization cannot fix, you usually do not need a rewrite. You move that function. PyO3 and maturin can expose Rust code as a Python module in an afternoon:
use pyo3::prelude::*;
#[pyfunction]
fn tokenize_batch(docs: Vec<String>) -> Vec<Vec<u32>> {
use rayon::prelude::*;
docs.par_iter().map(|d| tokenize(d)).collect()
}
#[pymodule]
fn fastpath(m: &Bound<'_, PyModule>) -> PyResult<()> {
m.add_function(wrap_pyfunction!(tokenize_batch, m)?)
}pip install maturin
maturin develop --release
python -c "import fastpath" # your Rust, now a Python moduleWhen Python is still the right default
Python is still the language most AI/ML teams should start with. The research ecosystem pulls that way: new papers ship with PyTorch repos, Hugging Face hubs are built around Python APIs, and notebooks remain the fastest place to test an idea. Rust's compile times and learning curve are real costs, and fighting the borrow checker while debugging a diverging loss function is a bad trade.
For exploration, experimentation, training orchestration, and anything where human iteration speed matters more than runtime speed, Python remains the better default. Rust earns its place on the hot paths underneath, not as a wholesale replacement.
Bottom line
Python still rules AI/ML at the layer where humans work. Choose per layer, not per project. Keep Python for notebooks, experiments, and orchestration. Reach for Rust for tokenizers, data pipelines, serving hot paths, and any place where throughput, concurrency, and memory safety are operational requirements. Profile first, find the bottleneck, and move only that piece across the boundary.